今天就來講講監督式學習,並且提及一下相關的歷史背景,最簡單分辨監督式學習與非監督式學習的方法就是蒐集的資料是否有labels存在,有就是監督式學習、沒有就是非監督式學習。
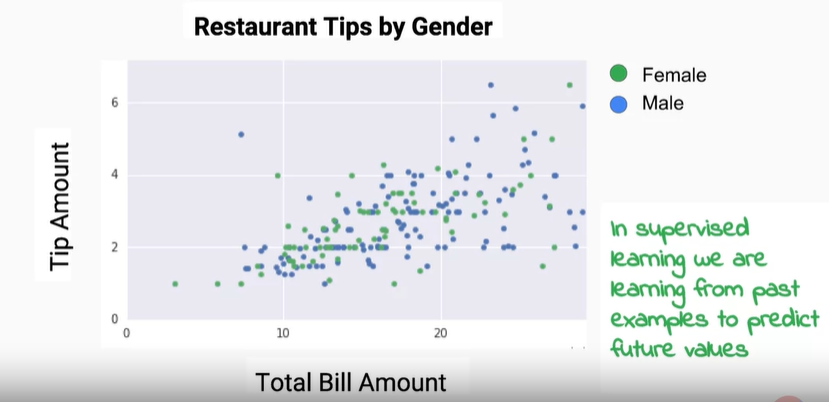
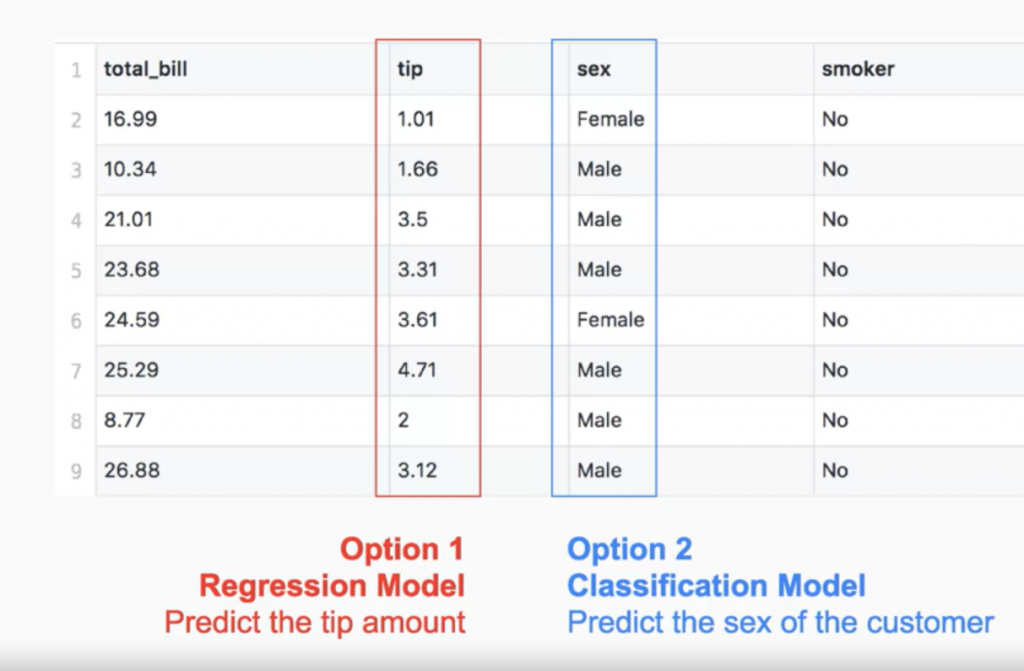
我們可以參考以下這張圖,這張圖在說明一家餐廳男女生給小多寡,可以非常明顯看到圖中,依照小費多寡與帳單的金額,用餐的男女都被標註起來作為分析的標準,而小費的數量可以拿來做回歸,性別可以來做分類,模型的建構都是取自於最後是想要哪種輸出來做決定的。
如果聽起來很抽象怎麼辦?
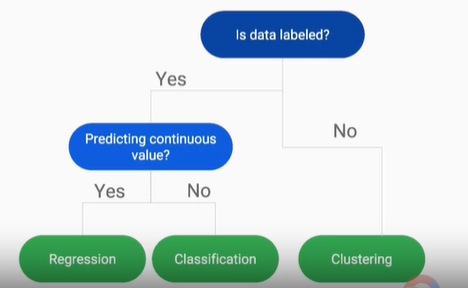
這裡有一個很好的樹狀圖來解釋,非常簡單如果今天資料不用被標記來做計算,就是屬於clustering(群聚分析),如果需要被標記,就會再細分想要的預測結果是連續性的數值嗎?若是的話則被分至回歸分析的問題,若不連續則是一個分類問題。
當然今天的重點會擺在回歸與分類的問題上,若是要使用上述餐廳給予小費的例子來做解析大家有發現甚麼問題嗎?
最重要的問題就是兩個族群離得太近了,今天若是我想要推算男生給予小費的區間或是找出男女給予小費的中間點,這是不是有點困難,這樣對於誤差範圍就有可能非常大,所以擁有好的資料集也是非常重要的。
那甚麼樣的資料適合來做機器學習呢?
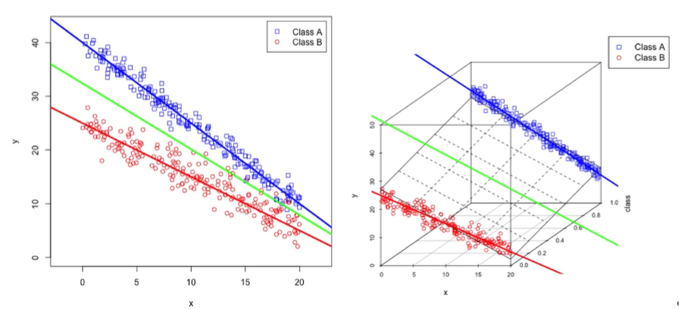
答案是標籤後本身資料特性就有差別的數據,若是做分類問題的兩個維度特徵最好是有所差異的,若映射到高維的地方,彼此的特徵是連續的又可以對此族群進行迴歸分析,所以下方這張圖不論是做迴歸分析或是分類問題都是很好的樣本。
而線性的概念1800s的人早就發現若是資料有連續的特徵,就可以拿來應用在很多現實生活中的案例,即使到現在線性回歸的概念也滿常被拿來用在股票上。
但其實線性的概念其實大家國中就會了,其實就是直線方程式的原理,只是多了一些參數,利用底下這個方程式就可以畫出線性的直線了。
並且利用loss function來評估是否跟原本數據的誤差是否夠小,下方公式的Xω就是上圖的ŷ。
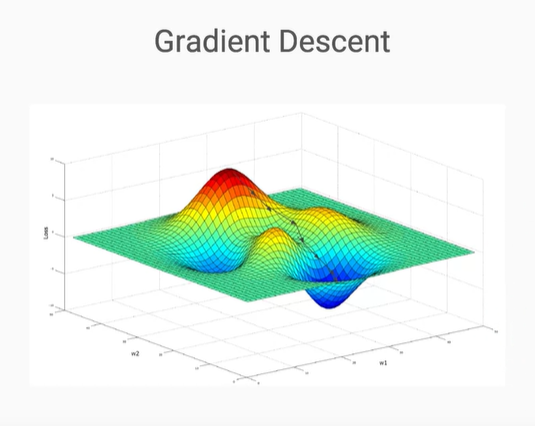
接著因為y與x是已經固定的數值,能夠變動的只有ω這個參數,最常被使用的就是梯度下降法,簡而言之,就是要在下圖中這個凹凸不平的地方找到最小值或是最大值透過更改ω這個參數,這裡給大家一個網站仔細的講述整個數學過程的網站作為參考。
※圖片參考至 Launching into Machine Learning slide